
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- install
- Spark
- webhdfs
- Linux
- python2
- CRT
- PFX
- setdefault
- kerberosClient
- kerberos
- OutOfMemory
- hadoop
- distcp
- hive
- OOM
- python3
- Keygen
- encoding
- ssh
- Python
- pyhive
- Celery
- executor
- OpenSSL
- airflow
- supserset
- unquote
Archives
- Today
- Total
복싱하는_개발자.dev
[Spark] spark cluster vs client mode 본문
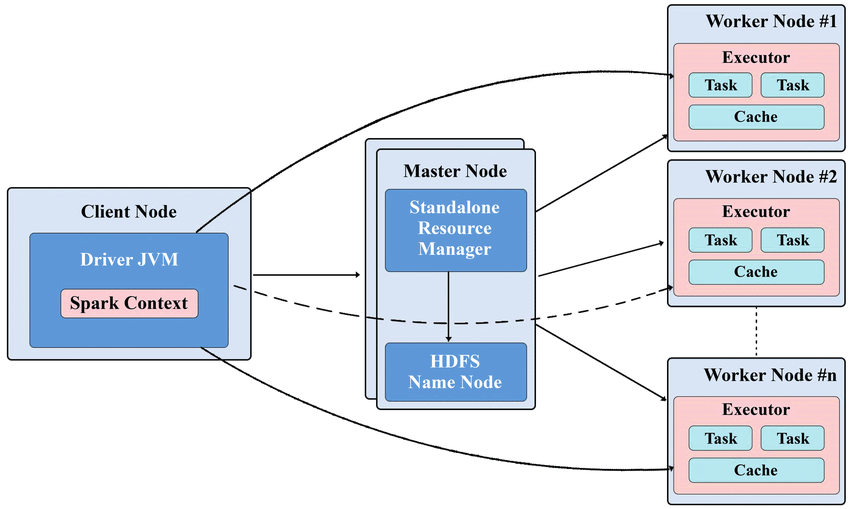
스파크를 실행하기 위해서는 스파크가 어떤 환경에서 실행이 되는지, 우리가 만든 Job이 어떻게 실행 될 건지에 대한 옵션을 Spark 실행 시 선언 해주어야 한다.
1. master option
spark-submit --master {local/standalone/yarn/mesos/k8s}* local : spark 사용 시 cluster 를 사용하지 않음.
즉, 분산처리를 하지 않고 내가 지금 spark 를 실행시키는 지금 이 환경에서 작업을 수행시키겠다.
* yarn / mesos / k8s: spark 사용 시 cluster 를 사용.
* --master 옵션을 선언하지 않았을 때, default 값은 standalone 이다.
2. deploy option
spark-submit --deploy-mode {client/cluster}deploy-mode의 차이는 spark-driver 가 어느 위치에서 생성되는지에 대한 차이이다.
* client mode: 실행을 호출한 곳(client)에서 spark driver 를 생성
* cluster mode: 실행을 호출한 곳(client)가 cluster container 에서 driver가 생성된다.
* --deploy-mode의 default 값은 client 이다.
'Spark' 카테고리의 다른 글
| [ERROR] PickleException: expected zero arguments for construction of ClassDict (for numpy.dtype) (0) | 2022.03.28 |
|---|---|
| [Spark] spark 작업 시 Java OOM(Out Of Memory) ERROR 처리 (0) | 2022.03.16 |
Comments